
administrator functions
|
Import Data |
Last Revised: 01/11/16 |
This application is used to import data into BBx/BBj data files. The source data is typically a comma or tab delimited text file created using the Export Data option on this menu, or by another application, or by saving a spreadsheet in tab delimited format. The target data is a single data file, previously described in the Dynamo Tools Data Dictionary. Field validation is performed and an Exception Listing can be generated listing all validation exceptions.
Note that this application can add new records to a file, or replace the entire record. It does not support modifying existing records. When not using the Replace option, existing records will be reported on the Exception Listing.
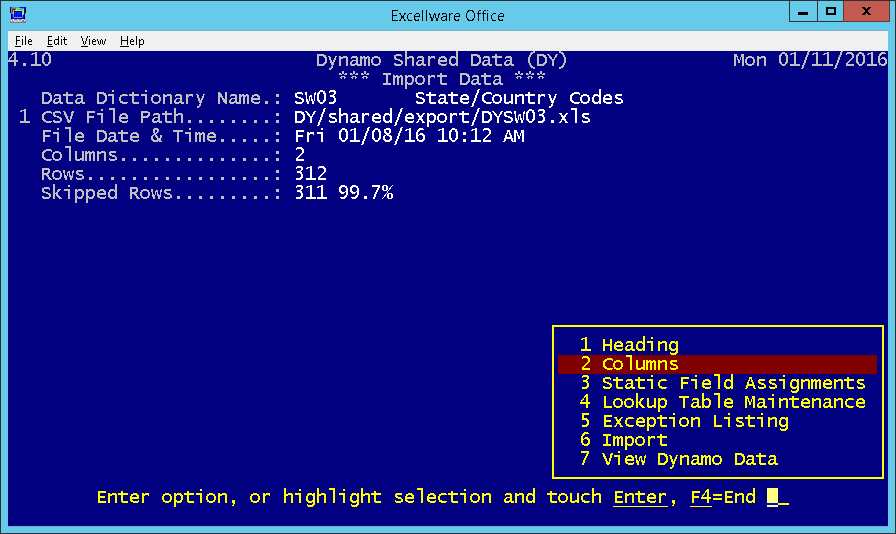
| Data Dictionary Name | A single Data Dictionary Name previously defined in the current company. File types MKY, VKY, XKY, and JKY can be used. |
| CSV File Path | Enter the path to the Comma Separated Value (CSV) text file. Note that a CSV file can also be delimited using the tab character which is actually the preferred format, as it makes it easier to process quote characters contained within a field. These files typically have either a .csv or .txt extension, although not required for use with this application. CSV files that are exported by the Dynamo Tools Export Data Utility typically have a .xls extension, but they are just tab-delimited text files. The .xls extension is used so that the file can be more easily accessed using a spreadsheet program. |
| File Date & Time | Displays the date/time of the CSV file specified |
| Columns | Displays the number of columns derived from the CSV file. Note that each row in the file must have the same number of columns. |
| Rows | Displays the number or rows (records) derived from the CSV file. |
| Skipped Rows | Set by this application to the number of rows that will not be, or were not imported due to a validation exception such as the number of columns is not the same as other rows, a key segment is blank or zero, the record already exists, etc. |
Columns
This section is used to map the CSV file column to a specific field name.

| Spreadsheet Column |
Columns in a spreadsheet are typically assigned a letter with the first column as 'A', the 26th column as 'Z', the 27th column as 'AA', followed by 'AB', 'AC', etc. Note that all columns in the CSV/spreadsheet file do not need to be mapped. Unmapped columns will be ignored. Note that it is permitted to have multiple columns map to the same field name. In that case, the columns are processed from left to right. If a column is mapped to a field that already has a non-blank value, then the field will be appended with a single space character followed by the new column text. Leading and trailing spaces are typically excluded during the map process. |
|||||||||||||||||||||||||||
| Heading Row | Most CSV/Spreadsheet files include field names in the first row. The value of the specified column in the first row is displayed. | |||||||||||||||||||||||||||
| Count | The number of rows with non-blank values and the percentage of total is displayed. | |||||||||||||||||||||||||||
| Min/Avg/Max Size | The number of characters in the field, showing the minimum, average, and maximum sizes. | |||||||||||||||||||||||||||
| Options |
One or more of the following options may be specified
|
|||||||||||||||||||||||||||
| Dynamo Field Name | The field name the column is to be mapped to | |||||||||||||||||||||||||||
| Dynamo Field Size | The Dynamo field size is displayed | |||||||||||||||||||||||||||
| Import Data | The first few rows that contain data are displayed. A red vertical line indicates fields that are longer than the Dynamo field size. |
Static Field Assignments
In addition to mapping columns from the spreadsheet to Dynamo fields, it is often necessary to assign other Dynamo fields to a default value.
Note that it is possible to have a Static Field Assignment as well as mapping the same column. In that case, the Static Field Assignment will
only be used when the spreadsheet data is blank or zero.
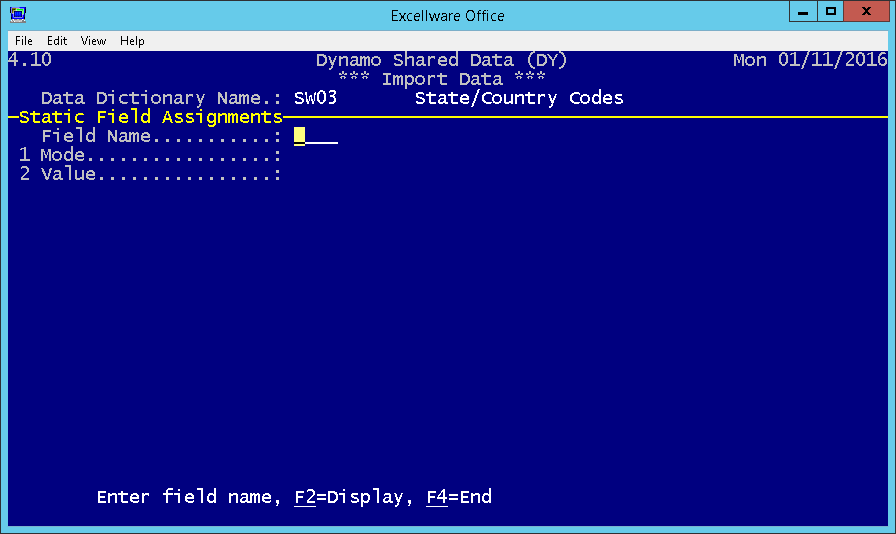
| Mode |
|
||||||
| Value | The static value to be assigned to each record (Mode=1), or the starting value (Mode=2 or 3). |
Lookup Table Maintenance
This option is still under construction. It will be used to maintain a user defined mapping of CSV file values to bbx field values.
Exception Listing
This option will analyze the data and produce a listing identifying rows and columns that contain invalid data. There are many reasons why a field may be invalid including that it is too long for the bbx data file, Non-numeric data mapped to a numeric field, field smaller than the minimum length or value as specified in the Data Dictionary, invalid State/Country Code, invalid email address, etc.
Rows can also be exceptions for reasons such as the record with that key already exists, there are blank or zero key segments, etc.
Note that T-Type routines can also perform field validation. Refer to CDX100 for more details.
Import
This option will process the CSV file and import (write) bbx records.
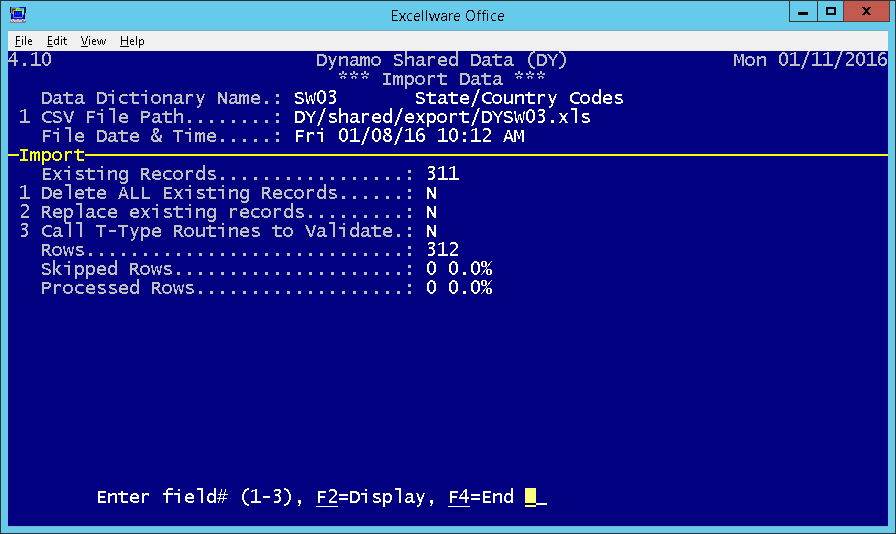
| Existing Records | Displays the number of records that exist in the bbx data file. |
| Delete Existing Records | In some cases you want to delete ALL all existing records in the import to data file before importing. A copy of the import to data file is made for safety. The copy will be located in the same directory as the original file with a .YYMMDDa suffix. |
| Replace Existing Records |
Set to Set to |
| Call T-Type Routines to Validate | The Import Data process validates fields based on the Data Dictionary. External T-Type routines can also be used to perform validation. Refer to CDX100 for more details. In some cases, there are older T-Type routines that do not support the "V" validation action code. In that case you will need to set this option to N in which case the T-Type external routines will not be called to perform additional validation. |
| Rows | The number of rows in the CSV/spreadsheet file |
| Skipped Rows | The number of rows that were skipped and not written to the bbx data file due to validation exceptions. The Exception Listing is also generated after the import process. |
| Processed Rows | The number of rows that had valid data and were written to the bbx data file. |
View Dynamo Data
This option can be used to view the bbx data, either before or after the import process.